고정 헤더 영역
상세 컨텐츠
본문

처음에는 for문을 사용해서 풀었다.
1. 문제 분석
1) 파일의 개수 N이 주어진다.
2) 둘째 줄부터 파일의 이름(소문자+점)이 주어진다.
3) 확장자를 기준으로 분류하고, 확장자가 여러개인 경우 확장자 이름의 사전순으로 (확장자 이름 + 개수)를 출력한다.
2. 제약 조건
1 <= N <= 50000
3 <= 각 파일 이름의 길이 <= 100
점은 한 번 등장하며, 파일 이름의 처음 또는 마지막에 오지 않는다.
3. 의사결정
1) N을 입력받고, N만큼 for문을 돌린다.
2) hashMap을 만들어서 key에는 확장자를, value에는 여러개의 파일명을 넣어준 뒤
3) key를 사전순으로 정렬하고
4) key값 + value개수 출력한다.
4. 문제 해결
1) hashmap을 key기준으로 오름차순 정렬할 경우 Collection.sort(), 내림차순 정렬할 경우 Collection.reverse() 메소드를 사용한다.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.*;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
HashMap<String, ArrayList<String>> hash = new HashMap<>();
// N 받기
int N = Integer.parseInt(br.readLine());
// for문
for (int i = 0; i < N; i++) {
// .을 기준으로 파일명과 확장자로 구분
StringTokenizer st = new StringTokenizer(br.readLine(), ".");
String name = st.nextToken();
String type = st.nextToken();
// 만약 key에 해당 type가 없는 경우 type 먼저 새로 만들기
if (!hash.containsKey(type)) {
hash.put(type, new ArrayList<>());
}
// 해당 type에 value 추가
hash.get(type).add(name);
}
// hashmap을 key 기준으로 정렬
List<String> keySet = new ArrayList<>(hash.keySet());
Collections.sort(keySet);
// 정렬된 keySet에 따라 [확장자명 + 파일개수] 출력
for(String key : keySet) {
System.out.print(key + " " + hash.get(key).size());
System.out.println();
}
}
}
코드가 조금 복잡한 것 같아서 좀더 간결하게 나타내보았다.
평소 외면하던 람다식, 스트림과 같은 개념을 다시 공부하면서 코드를 작성했다.
1) hashmap의 value부분에 파일 이름을 모두 넣지 말고, 해당 파일의 개수를 count하면 더 간단하다.
2) 처음에는 메모리가 더 적은 StringTokenizer를 사용하여 .을 기준으로 파일명과 확장자를 구분했는데,
코드가 더 간결하고 정규 표현식을 사용하는 split을 사용해보았다. (장단점이 있는 듯 하다)
3) "\\."을 사용한 이유 : 정규 표현식에서 "."은 임의의 문자 하나를 나타내므로, "\\." 으로 이스케이프 처리를 해야 파일명/확장자를 "."으로 정확히 구분 가능하다.
4) hash.getOrDefault : type이 없을 경우 value를 0으로 초기화하고, type이 존재할 경우 +1 증가시키는 방법을 합친 코드이다.
5) stream을 사용하면 for문보다 간결하다고 한다. keySet을 stream으로 변환한 뒤 중간 연산으로 .sorted()를 수행하고, 최종 연산으로 .forEach()를 수행한다.
6) 람다 표현식 key -> System.out.println(key + " " + hash.get(key));으로 함수를 간단히 사용했다.
stream()에서 람다 표현식이 같이 사용되는 경우가 많다고 한다.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.*;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
HashMap<String, Integer> hash = new HashMap<>();
// N 받기
int N = Integer.parseInt(br.readLine());
// for문
for (int i = 0; i < N; i++) {
String type = br.readLine().split("\\.")[1]; // .을 기준으로 나눔
hash.put(type, hash.getOrDefault(type, 0) + 1); // 확장자와 파일개수
}
// hashmap을 key 기준으로 정렬하고 출력
hash.keySet().stream().sorted().forEach(key -> System.out.println(key + " " + hash.get(key)));
}
}
stream과 람다 표현식에 대해서는 곧 다시 정리해봐야겠다.
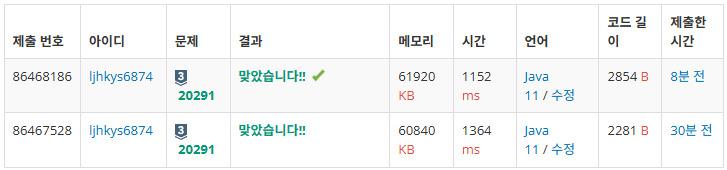
두 풀이 간 메모리와 시간은 비슷한데,
아래 풀이에서 코드가 더 간결하고 가독성이 좋은 듯 하다.
'Algorithm' 카테고리의 다른 글
| 29701. 모스 부호 (0) | 2024.11.16 |
|---|---|
| 2605. 줄 세우기 (0) | 2024.11.16 |
| 2908. 상수 (0) | 2024.11.15 |
| 1152. 단어의 개수 (0) | 2024.11.15 |
| 26041. 비슷한 전화번호 표시 (1) | 2024.11.15 |




